Table of Contents
Part 1: Introduction and Functional SpecsPart 2: Java classes
Part 3: XML configuration
Part 4: Running the Application
Dependencies
- Spring core 3.1.0.RELEASE
- Spring Batch 2.1.8.RELEASE
- See pom.xml for details
Github
To access the source code, please visit the project's Github repository (click here)
Functional Specs
Before we start, let's define the application's specs as follows:- Import a list of comma-delimited records
- Import a list of fixed-length records
- Import a list of mixed-type records
- Jobs must be triggered using a web interface
- Display the imported records in a web interface
- Each record represents a user and its associated access levels
Here's our Use Case diagram:

The CSV Files
To visualize what we want to do, let's examine first the files that we plan to import:User Files
user1.csvThis file contains comma-separated value (CSV) records representing User records. Each line has the following tokens: username, first name, last name, password.
user2.csv
This file contains fixed-length records representing User records. Each line has the following tokens: username(positions 1-5), first name(6-9), last name(10-16), password(17-25).
user2.csv
This file contains comma-separated value and fixed-length records representing User records. Each line has the following tokens: username, first name, last name, password.
This file contains two types of CSV-records:
- DELIMITED-RECORD-A: uses the standard comma delimiter
- DELIMITED-RECORD-B: uses | delimiter
It also contains two types of fixed-length records:
- FIXED-RECORD-A: username(16-20), first name(21-25), last name(26-31), password(32-40)
- FIXED-RECORD-B: username(16-21), first name(22-27), last name(28-33), password(35-42)
Role Files
role1.csvThis file contains comma-separated value (CSV) records representing Role records. Each line has the following tokens: username and access level.
role2.csv
This file contains fixed-length records representing Role records. Each line has the following tokens: username and access level.
role3.csv
This file contains comma-separated value (CSV) records representing Role records. Each line has the following tokens: username and access level.
By now you should have a basic idea of the file formats that we will be importing. You must realize that all we want to do is import these files and display them on a web interface.
Diagrams
Here's the Class diagram:
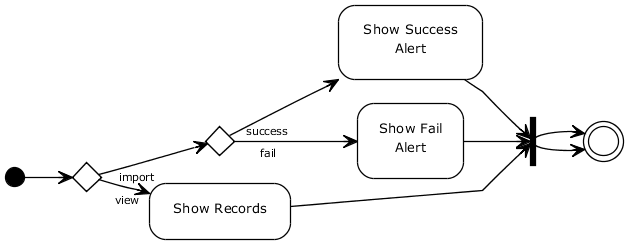
Here's the Activity Diagram:
Screenshots
Let's preview how the application will look like after it's finished. This is also a good way to clarify further the application's specs.Entry page
The entry page is the primary page that users will see. It contains a table showing user records and four buttons for adding, editing, deleting, and reloading data. All interactions will happen in this page.

Entry page





Next
In the next section, we will write the Java classes. Click here to proceed.|
Share the joy:

|
 Subscribe by reader
Subscribe by reader
 Subscribe by email
Share
Subscribe by email
Share

