Introduction
In this tutorial, we will create a simple CRUD application using Spring 3.1 and Neo4j. We will based this tutorial on a previous guide for MongoDB. This means we will re-use our existing design and implement only the data layer to use Neo4j as our data store.Table of Contents
Part 1: Introduction and Functional SpecsPart 2: Java classes
Part 3: XML configuration
Part 4: HTML (with AJAX)
Part 5: Running the Application
Dependencies
- Spring core 3.1.0.RELEASE
- Spring Data Neo4j 2.1.0.M1
- Neo4j Kernel 1.6
- Neo4j Cypher 1.6
- Neo4j Cypher DSL 1.6
- See pom.xml for details
Github
To access the source code, please visit the project's Github repository (click here)
Functional Specs
Before we start, let's define our application's specification as follows:- A CRUD page for managing users
- Use AJAX to avoid page refresh
- Users have roles: either admin or regular (default)
- Everyone can create new users and edit existing ones
- When editing, users can only edit first name, last name, and role fields
- A username is assumed to be unique
Here's our Use Case diagram:

Database
If you're new to Neo4j and Spring Data Neo4j and coming from a SQL-background, please take some time to read the following references:In its simplest form, Neo4j is a NoSQL graph database containing nodes and relationships.
What is Neo4j?
The Neo4j data model consists of nodes and relationships, both of which can have key/value-style properties. What does that mean, exactly? Nodes are the graph database name for records, with property keys instead of column names. That's normal enough. Relationships are the special part. In Neo4j, relationships are first-class citizens, meaning they are more than a simple foreign-key reference to another record, relationships carry information.
Source: Spring Data Neo4j - Chapter 4. Learning Neo4j
What is a Graph database?
A graph database stores data in a graph, the most generic of data structures, capable of elegantly representing any kind of data in a highly accessible way.
“A Graph —records data in→ Nodes —which have→ Properties”
“Nodes —are organized by→ Relationships —which also have→ Properties”
“A Traversal —navigates→ a Graph; it —identifies→ Paths —which order→ Nodes”
“An Index —maps from→ Properties —to either→ Nodes or Relationships”
“A Graph Database —manages a→ Graph and —also manages related→ Indexes”
Source: What is a Graph Database?

From Java to Neo4j
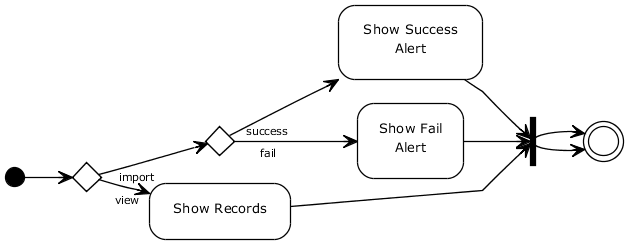
We have two Java classes representing our domain: User and Role. Here is the Class diagram:
In Neo4j, User and Role are nodes, and the link between the two is a relationship. In Part 2 we will demonstrate how to declare them as nodes and how to create the relationship.
Here's the Activity diagram:

Screenshots
Let's preview how the application will look like after it's finished. This is also a good way to clarify further our application's specs. Note: These are the same screenshots you will see from the Spring MVC 3.1 - Implement CRUD with Spring Data MongoDB guide (We're reusing the exact presentation layer).Entry page
The entry page is the primary page that users will see. It contains a table showing user records and four buttons for adding, editing, deleting, and reloading data. All interactions will happen in this page.

Entry page
Edit existing record
When user clicks the Edit button, an Edit Record form shall appear after the table.

Edit record form
When a user submits the form, a success or failure alert should appear.

Success alert
When the operation is successful, the update record should reflect on the table.

Edited record appears on the table
Create new record
When a user clicks the New button, a Create New Record form shall appear after the table.

Create new record form
When a user submits the form, a success or failure alert should appear.

Success alert
When the operation is successful, the new record should appear on the table.

New record shows on the form
Delete record
When user clicks the Delete button, a success or failure alert should appear.

Success alert
Reload record
When user clicks the Reload button, the data on the table should be reloaded.
Errors
When user clicks the Edit or Delete button without selecting a record first, a "Select a record first!" alert should appear.

Error alert
Next
In the next section, we will write the Java classes and discuss the application's layers. Click here to proceed.|
Share the joy:

|
 Subscribe by reader
Subscribe by reader
 Subscribe by email
Share
Subscribe by email
Share